人工知能の歴史・理論と技術 7
ディープラーニング(深層学習)の詳しい内容に入ります。
ディープラーニングは、音声、画像、自然言語に対する認識について、ほかの機械学習手法を圧倒する成功率・成績を修めています。しかし、これがこんなにも高い性能を示すのはなぜなのか、その理由の理論的解明は十分になされていません。なんとなく、「脳っぽいからいいんじゃない?」という感じでしょうか。少々、不気味ではあります。
多層ニューラルネットワーク
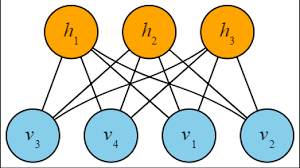
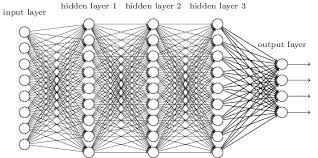
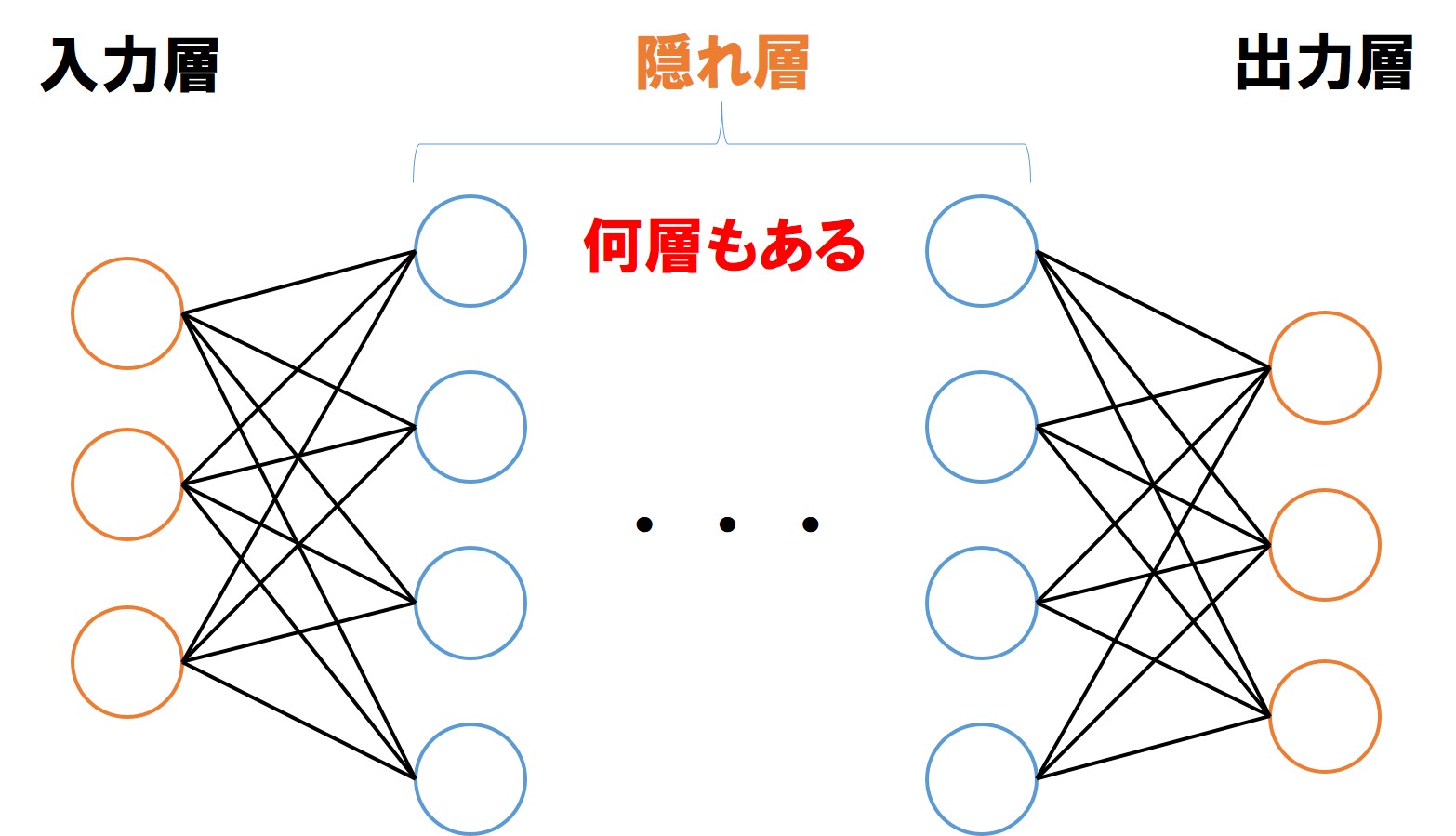
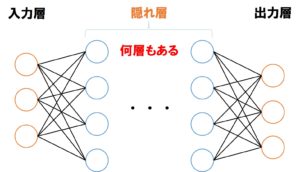
制限ボルツマンマシン RBMは可視層と不可視層の2層でしたが、ディープラーニングで用いるニューラルネットワークシステムは多層で、ふつうは4層以上あります。入力層、中間層、出力層から成っており、中間層を構成する個々のノードはパーセプトロンに用いられていたのと同じ、ふつうの人工ニューロンです。
画像や音声を認識・学習していく方法は制限ボルツマンマシンと基本的には同じで、バックプロパゲーションBack-propagation(前方伝播・後方伝播)の繰り返しの中で特徴量の変更を行っていくヒューリスティックなやり方により近似解の探索を行います。ただし後述するテクノロジーによっては、バックプロパゲーションを行わない「順伝播型」とされるものもあります。
https://www.souya.biz/%E6%A5%AD%E5%8B%99%E3%82%B7%E3%82%B9%E3%83%86%E3%83%A0/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%BB%E3%83%87%E3%82%A3%E3%83%BC%E3%83%97%E3%83%A9%E3%83%BC%E3%83%8B%E3%83%B3%E3%82%B0/
実際の利用・成果
ここまでの説明でお分かりいただけたと思いますが、ディープラーニングは「学習」であり、「認識」がテーマであって推論や判断をおこなうアルゴリズムではありません。自動推論のアルゴリズムを進化させていくことは、また別の課題になります。
しかし確度の高い推論・判断のためには知識データベースの充実が重要ですので、その意味でディープラーニングの実現は大きなブレイクスルーと言えます。
ディープラーニングは物体や音声の認識を中心に、さまざまな分野で活用されています。
たとえばGoogleのスマートフォン、タブレットPC向けOSであるAndroidは、バージョン4.3以降で音声認識にディープラーニング技術を応用しており、音声認識の精度を25~50パーセント向上させたといいます。「Ok, Google」とかっこいい英語の感じで言わなくても、「オッケー、グーグル」と日本人的カタカナ英語で言えば、最近のAndroidはわかってくれます。
ちなみにディープラーニングを発明したJ. ヒントンは大学教授を続ける傍ら、Googleにも勤めているのです。そのため、Googleの人工知能分野での業績はどうしても目を引きます。
そのGoogleは、2012年、1,000台のサーバーを使った大規模ニューラルネットワークに200ドット四方(4万ピクセル)の猫の画像1,000万枚を3日間で認識させ、猫の識別に成功したとしています。
またGoogleは2014年、画像をアップロードすると自動的にその画像の説明文を生成してくれる「Image to Text」というシステムを開発しています。これは画像認識と自然言語処理を組み合わせたものであり、画像・言語それぞれについてディープラーニングが応用されて組み合わせるための素材データが蓄積され、用いられています。
それから、中国のAI分野での躍進にはめざましいものがあります。人口が多いためビッグ・データの集積が速く、人権尊重の意識が低いため政府が国民のプライバシーを気にせず深いところまでデータ集めの手を伸ばせるところが有利に働いています。中国ではメールのやりとりはもちろん、電話での通話も当局にチェックされかねません。音声認識はディープラーニングの得意とするところですから。
さらに中国には全国に20億台ちかくの監視カメラがあると言われます。ディープラーニング技術で人の顔の認識も自動化できますので、犯罪者や反体制派の居所があっという間に当局に把握されるということも、もう実現しているようです。

http://labaq.com/archives/51808947.html
また、Facebookはユーザーがアップロードした画像をディープラーニングによって認識させ、画像に写っているものが何かを識別する精度を高めています。Facebookは2015年1月にディープラーニングモデルの開発環境をオープンソースとして公開し、広く一般に提供しました。この開発環境はGPUを用いればそれまでのコードの23.5倍もの高速処理が可能とされ、ディープラーニング研究開発の強力なツールになると期待されています。
(注:オープンソースは、プログラムのソースコード、つまり高級言語で書かれた機械語変換前のコードが公開されているということを意味します。ソースコードを商用・非商用を問わず利用、改変、修正、頒布することができるわけで、言ってみれば世界中のプログラミング技術者が寄ってたかってひとつのソフトウェアを洗練させていくことができるというソフトウェアの開発手法になります。具体例としては、Unix系OSであるLinax(リナックス、またはライナックス)や、Mozillaが「Firefox」をオープンソース化して頒布することを認めた「Iceweasel」といったものが代表的です。)

https://www.slideshare.net/YutakaKachi/45-101
さて、次の記事では、引き続きディープラーニングに関して解説していきます。システムのデザインや、使用されているテクノロジー、および周辺の理論・技術などです。