人工知能の歴史・理論と技術 6
現在たけなわとなっている第3次AIブームを見ていきます。前述のように、これは2006年、ジェフリー・ヒントンによるディープラーニングの発明に端を発します。
前の記事でも簡単に触れましたが、ディープラーニングの出発点となった「制限ボルツマンマシン」に見られる発想から解説していきます。
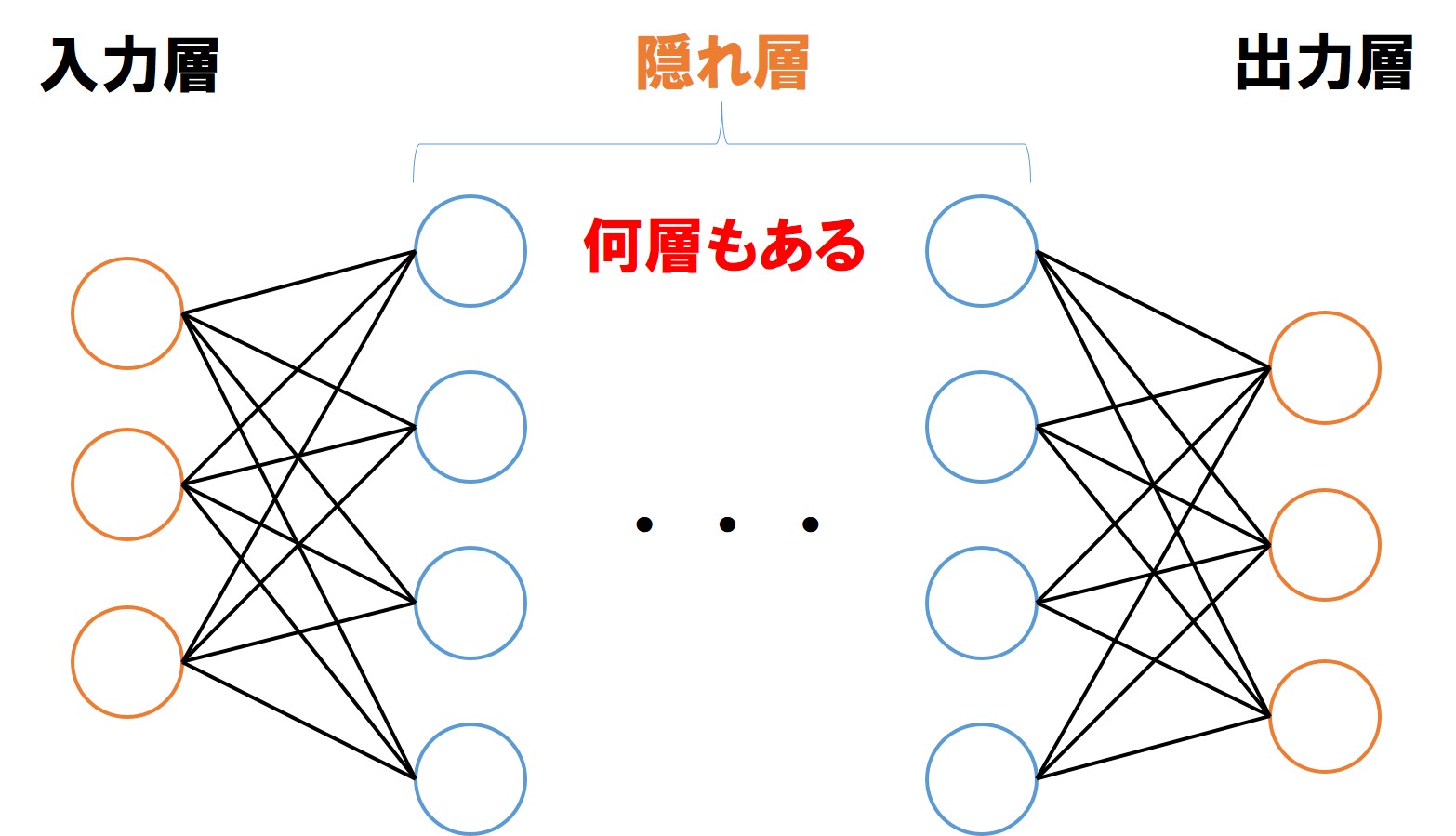
ニューラルネットワークによる自動学習
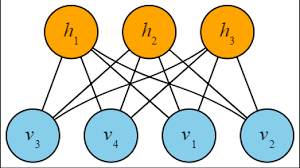
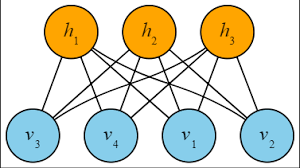
制限ボルツマンマシン(Restricted Boltzmann Machine・RBM)は、可視層(入出力層・visible layer)と不可視層(処理層・hidden layer)の2層に配された多数のノードユニットを、同一層内では接続せずに2層間ですべて相互に接続する形式で作られたニューラルネットワークです。
http://ai-master.jp/wiki/index.php?%E3%83%9C%E3%83%AB%E3%83%84%E3%83%9E%E3%83%B3%E3%83%9E%E3%82%B7%E3%83%B3
この制限ボルツマンマシン(RBM)を使った自動学習は、
①可視層から不可視層へデータを伝達
②不可視層で重み付け処理と関数演算(ここまでを「前方伝播」と言います)
③②の結果算出された確率分布を不可視層で逆算(バックプロパゲーション Back-propagation)
④可視層に逆送(③と④が「後方伝播」です)
というステップを、①で入力したデータの確率分布が④で返されたデータの確率分布で再現されるようになるまで重み付け値(特徴量)を修正しながら何度も繰り返すことで行われます。
特徴量(Weighting Factor)の初期値は、不可視層のノードそれぞれについてランダムに設定されていて、①と④が合致ないし近似しているところの特徴量は保存され、①と④が合致しない部分(Contrastiveな部分・対比的な部分)のノードの特徴量は、上記ステップの往復1回ごとに、①に近づけるように自動修正されます(コントラスティブ・ダイバージェンス法)。
https://postd.cc/a-beginners-guide-to-restricted-boltzmann-machines/
こうして修正しながらの繰り返し往復処理を重ね、①と④が十分に合致したら(平衡確率分布に達したら)、学習OKということになります。その時の不可視層全ノードの特徴量設定が完成の形です。
ヒューリスティック(heuristic)な試行錯誤の繰り返し、つまり「暫定的解」と「修正」の繰り返しによって、自動学習がなされます。基礎的な部分で、人工知能研究草創期の発想が引き継がれているわけです。
現実的応用の具体的概略は以下のようになります。
可視層には、入力するデータの分布範囲に応じた数のノードが置かれます。たとえば、画像認識ならばタテ×ヨコのピクセル数と同じ数だけ、音声認識ならば音の強さや周波数をとらえる単位時間(100分の1秒とか)に分割した数だけ用意されます。画像のピクセルが100×100なら10,000個、単語を発音している音声が1秒で分割単位時間が100分の1秒なら100個のノードということです。
ここでは画像を例にとりましょう。手書き文字の数字「3」を読めるように、RBMに学習させます。まずはデータの用意です。100×100ピクセルの正方形上に手書きで「3」が書かれたデータをたくさん用意します。それぞれは(人には)十分に判読可能ですが、ひとつひとつ微妙にクセがあり、異なっています。それでもRBMが読めるようになることが目標です。
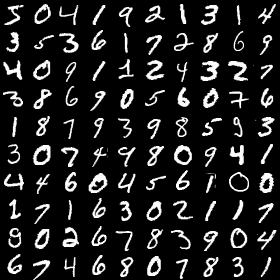
http://yaju3d.hatenablog.jp/entry/2016/04/22/073249
あとはもうお分かりでしょう。ひとつひとつの「3」をRBMに見せながら、平衡確率分布に達するまで上記の①~④のステップで学習させ、ひとつ学んだら次、ひとつ学んだら次と繰り返していくことで、「微妙にクセがあってひとつひとつちがうのに、“3”と読めるピクセルの確率分布」が少しずつ確立されていきます。ピントのぼけた“3”の形で、周囲に行くにつれて薄くなっていくようなグラデーションの、雲状の確率分布になります。

http://www.uosansatox.biz/entry/2017/10/06/070000
そして最終的には、RBMはいろいろな人の手書きの「3」が読めるようになります。
ディープラーニングへ向けて・環境の変化
制限ボルツマンマシンの自動学習によって、人が特徴量(重み付け値)を与えてやらなくとも、機械が自力で見つけてくれるようになりました。ディープラーニングはこの延長上にあると言え、その本質にはこの自動学習の仕組みがあります。
ただ、現在行われているディープラーニングを実現するには、環境の変化も必要でした。その環境の変化とは、
・コンピュータの処理能力向上
・GPU(グラフィック処理を行う専用プロセッサー)の進歩
・インターネットの情報量の増大
といったものです。
「コンピュータの処理能力向上」というのは、主にCPUの話です。これまではLSIの集積密度やクロック周波数を高くすることで高速化がはかられてきましたが、それらの高さは限界に近づいています。そこで、ひとつのCPUの中で複数のCPUが動作しているかのように稼働する「マルチコア化」で能力向上を図るようになってきています。デュアルコア(CPU2つ)、クアッドコア(4つ)、オクタコア(8つ)といった具合です。多くなるほど処理能力は向上します。
またGPUについてですが、RBMにせよディープラーニングにせよ、前方伝播・後方伝播の繰り返しには行列演算が多用されます。グラフィックスというのは多次元×多次元の演算を必要としますので、GPUは最初から行列演算が得意なようにできています。行列演算だけで比べれば、GPUはCPUの10倍の処理速度があります。もちろん、画像認識の効率にも貢献します。こういうGPUの進歩も、ディープラーニングに追い風を送っています。
そしてインターネットの情報量増大。「10年で500倍」とも言われるペースで増大し続けています。かつて1990年代は文字のやりとりが中心でしたが、次第に写真が見られるようになり、そして動画の時代が来ました。移動体通信規格5Gの時代が来たら、ますます増えるでしょう。IoTの広がりから、人が入力するのではなく、身の回りのデバイスや電化製品、あるいは車両、衣服などIoT化されたグッズが入力するデータも飛び交うようになります。
この大量のデータは、機械学習・自動学習にとって、まさに「宝の山」です。世界中のユーザーが無尽蔵に提供してくれるデータは「限りない資源」。自動データマイニングによって、数多くの発見をすでにしており、これからもしていくでしょう。
さて、ディープラーニング実現の背景環境の話はこれまでとしまして、次の記事ではディープラーニングの内容に入っていきます。