では、機械学習に用いられる個別技術を見ていきましょう。「ヒューリスティック」のところで触れた遺伝的アルゴリズムを応用した機械学習もありますが、大部分は確率分布の抽出など統計学的手法を用います。一部をサンプリングするのではなく、ビッグデータ全体を受け止める場合もありますが、いずれにせよデータの集合体を相手にするわけですから、どうしても統計学に頼らざるをえないのです。
ただ、ニューラルネットワークなど、ヒューリスティックな手法との合わせ技のものもあります。
テキストマイニング
テキストを対象としたデータマイニングがテキストマイニングです。単語の使用頻度、単語同士の文法的関係(主語、動詞、目的語、修飾語など)、相関、傾向、時系列にそった変化などを解析します。
書かれている意味内容まで把握しながらの解析はまだ人間に及びませんが、英語ではかなり高いレベルでできるようになっています。日本語に関しては、単語の区切りや文法的なゆらぎの大きさといった問題から、英語に比べると高度な解析は困難でした。しかし、自然言語処理技術も向上しており、定型的な文書であれば実用に耐えるレベルのテキストマイニングが可能になってきました。
テキストマイニングの対象としては、顧客からのアンケートの回答やコールセンターに寄せられる質問や意見、電子掲示板やメーリングリストに蓄積されたテキストデータなどがあります。
こちらには無料でテキストマイニングを体験できるサイトがあります。無料版なのでたいしたことはできませんが、主要キーワードや単語同士の結びつきが視覚的イメージで俯瞰できるようになっています。
サポートベクターマシン
分類や回帰を学習するアルゴリズムです。基本的には線形分離可能、つまり3次元に散らばっているデータが平面(2次元)で区分できたり、2次元(平面)に散らばっているデータが直線(1次元)で区分できたりするケースで、その平面や直線を算定して分類や回帰ができる関数を決めます。発展的なものでは線形分離不可能なケースでも分類・回帰できます。
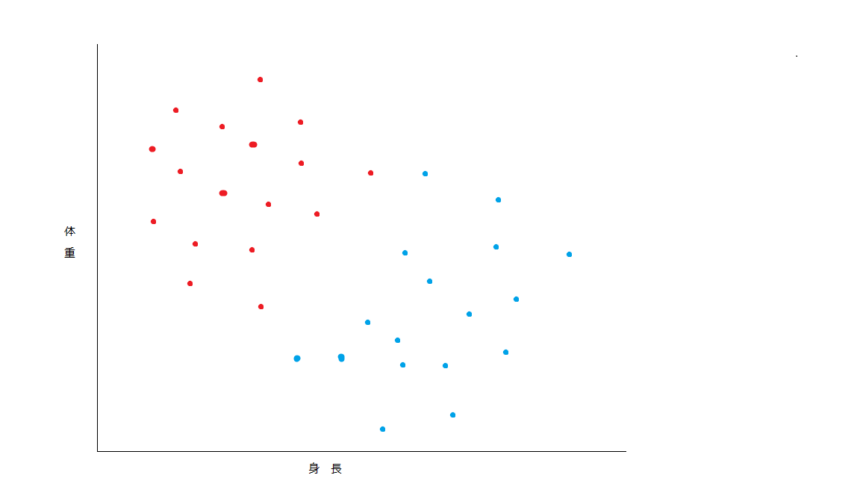
ここではわかりやすく2次元で説明します。ここに2つの星からきた宇宙人、プーパッポン星人とカオニャオマムアン星人がいるとします。プーパッポン星人は高重力惑星の出身で、身長は低く体重は重い種族で、カオニャオマムアン星人は低重力惑星出身で身長が高く体重は軽めです。すると両者は下のグラフのように分布します。
赤がプーパッポン星人、青がカオニャオマムアン星人です。
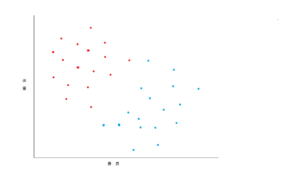
この両者を分類する線を引くという問題です。プーパッポン星人にしてもカオニャオマムアン星人にしても、ある程度平均から外れた身長・体重の持ち主のデータが加わっても、引き直さずに有効に分類できるような線を引くのが目標です。
見ればだいたいどの辺に線を引けばいいか、イメージはつかめるでしょう。しかしここは、しっかり計算して引きたいのです。その方針としては、
① 両者のうち、たがいにもっとも近い個体をひとつずつ選ぶ
② その個体両方からもっとも遠くなるように線を引く
……です。
この方針でいくと、次のようになります。
Aのプーパッポン星人とBのカオニャオマムアン星人が互いにもっとも近いので、この間に、線からA、線からBがもっとも長く、かつ同じ距離になるように線を引きます。
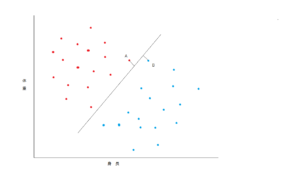
このように分類したり、回帰分析したりするのがサポートベクターマシンのアルゴリズムです。
クラスタリング
クラスタリングは、観測されたデータを「クラスター」と呼ばれる部分集合のグループに分類する作業を言います。上のサポートベクターマシンは2種の分類が基本ですが、クラスタリングはもっと多数のクラスターに分類することを目指します。
クラスターの定義が重要で、同じクラスターに属する要素が十分に類似しているように、あるいは、他のクラスターから十分に距離が離れているように設定します。
クラスタリング(クラスター分け)の一例は別のところで書いたk平均法です。200の農場を5つの農協に振り分けて所属させ、かつ所属農場にとってもっとも近くなるような集荷場の位置も算出するアルゴリズムになっています。
この例では、クラスターの数は最初に設定されていますが、その位置は繰り返し計算によって順次変わり、同時にクラスターの内容要素も変化します。変化しなくなったところで完了ということで、この過程はヒューリスティックでもあります。
ニューラルネットワーク
人工ニューラルネットワーク(Artificial Neural Network)とも呼ばれます。生物の神経ネットワークの仕組みと機能を模倣するというコンセプトで考えられたアルゴリズムになります。こちらで書いたSNARCや、こちらに書いたパーセプトロンが発展して高度化・複雑化したものです。福島邦彦が1979年に発表したネオコグニトロンも原点のひとつです。
画像や物体の認識、動画認識、文字認識、音声認識を行うディープラーニングに応用されます。そういった多次元・多変量のデータや関数も扱い、特徴量も自分で計算して最適化できる点が画期的です。
特徴量を修正する計算は、バックプロパゲーションBack-propagationというやり方で行われます。出力データとお手本データを比べて(つまり「教師あり学習」です)、誤差の小さい部分の特徴量は保存し、誤差が大きい部分については最急降下法などを用いて特徴量を修正していきます。
繰り返しバックプロパゲーションを行うことで特徴量を最適化していくという手法は、ヒューリスティックでもあります。また、非常に多数のトレーニングデータを処理しながら、認識対象物の特徴の確率分布をパターンとして認識していくという点では、統計学的手法も活かされています。
現在のところ、こちらで書いた畳み込みニューラルネットワーク Convolutional Neural Network (CNN)と呼ばれるタイプのニューラルネットワークがすぐれた成績を残しています。しかし、スパイキングニューラルネットワークという、神経のネットワークだけでなく「脳波」まで模倣した、より生物の脳にちかい仕組みを持たせたモデルが、CNNよりも広い範囲の問題に応用できるとされ、次世代の技術として研究されています。
まとめ
主に統計学的手法に関係する人工知能技術はいったんここまでにします。もちろん今回書いたもの以外にも機械学習の手法はありますが、「強化学習」などになると「確率的に振る舞わせて学習させる」ことになりますので、どちらかというと確率に強く関連します。したがって次回以降に回したいと思います。