統計学のテーマは「データ処理・データ分析」ですが、人工知能の領域で行われるそれと似通った作業というと、データマイニングやディープラーニングを含む機械学習になります。似たような作業を行うわけですから、機械学習ももちろん統計学を活用します。しかし、統計学的手法とは少し異なる方法論も出てきます。
ここでは、統計学と機械学習を比較して見ます。
機械学習と統計学
機械学習も統計学も、データを分析して傾向を読み取ったり、規則性や法則性を見つけたりする作業や手法では共通し、重なる部分が非常に大きくなっています。両者のちがいがどこにあるのか、しばしば議論されますが、よく言われるのが「統計学はデータの説明に重きを置き、機械学習はデータの予測に重きを置く」ということです。ベクトルが過去を向いているか未来に向いているか、ということでしょうか。
しかし、ドイツのヴァイツゼッカー大統領が言うように「過去に目を閉ざす者は現在に対しても盲目となる」わけですし、すぐ近くの未来も見えなくなるでしょう。過去を見つめる統計学も、単なる歴史的事実の記録にすぎないものではなく、現在を把握する手段であり、そして未来につながっていくはずのものです。ですから、「説明」と「予測」というのも、あまり本質的ではないちがいと言えそうです。
統計学の手法
長い伝統がある統計学の手法は、大きくわけて2種類あります。記述統計と推測統計です。
・記述統計
集めたデータから、母集団全体の特徴や傾向をつかみます。
度数分布
「犬が好き:75人、猫が好き:65人……」など、あるデータの出現数をカウントして比率を算出したりします。
クロス集計
「犬も猫も好き:50人、犬は好きだが猫はきらい:25人、猫は好きだが犬はきらい:13人……」といったように、複数の変数を組み合わせて集計します。
代表値
平均値、中央値、最頻値など、ひとつの値を出して集団の特徴を調べます。
散布度(ばらつき)
偏差値の出番です。たとえば、AというグループとBというグループがあり、両方とも平均年齢が20歳だったとします。しかし、Aグループの標準偏差は15.0、Bグループの標準偏差は2.0です。両グループにはどんなちがいがあるでしょうか。
前回の偏差値についての説明を見直していただければわかると思います。Aグループは年齢のばらつきが大きく、幼児からお年寄りまでメンバーに含まれていると考えられます。Bグループは年齢のばらつきが小さく、全員が大学生かもしれません。
・推測統計
推定や仮説検定によって、集めたデータから母集団の特徴を推測します。
仮説検定
無作為抽出した100人のアンケート調査で「たけのこの里が好き:68人」、「きのこの山が好き:32人」という結果が出たとします。「無作為抽出」というのがポイントで、性別や年齢や職業に偏りが少ないならば、「この100人でたまたま見られた傾向」ではなく、「日本全国でそうなんじゃね?」と推測できるのです。
相関分析・回帰分析
複数の変数間の関連性を調べるときには相関分析や回帰分析を行います。たとえば気温・湿度と電力消費量には相関性があります。「どのくらい気温が上がると、どのくらい電力消費が増えるか」が知りたければ、気温と電力消費量のデータを回帰分析してやればわかります。実際に電力会社はそれを計算して発電量の調整に活かしています。
確率分布
サイコロを2つ振って出た目の合計がとる確率は、
2:2.77%
3:5.55%
4:8.33%
5:11.11%
6:13.88%
7:16.66%
8:13.88%
9:11.11%
10:8.33%
11:5.55%
12:2.77%
となります。「7」になる確率がもっとも高く、「2」や「12」は低くなっており、全体として正規分布に近い形になります。
白と黒の碁石を5個ずつ袋に入れ4つ取り出すときに見られるパターンでは、
白4黒0:2%
白3黒1:24%
白2黒2:48%
白1黒3:24%
白0黒4:2%
となり、これも正規分布に近い形になっています。
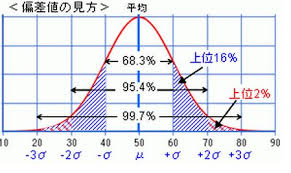
正規分布に近い形になっているということは、標準偏差が使えます。確率分布上、偏差値の高い、あるいは低い現象が予測よりも頻繁に起きているとすれば、「ん? 何かあるぞ」ということになります。
ちなみに、平均±標準偏差の範囲にはデータの68.2%、平均±2×標準偏差の範囲には95.4%、平均±3×標準偏差の範囲には99.7%が収まります。
統計学は、おおむねこれらのような手法でデータを解析します。
開票速報と開票作業
さて、次にここで人工知能の技術、特に機械学習について触れるべきところですが、「統計学的手法と機械学習のいちばんちがうところ」について先に押さえてしまいましょう。
いちばんちがうところは、「統計学的手法は母集団全体から一部をサンプリングしてデータ解析するのに対し、機械学習ではサンプリングせず母集団全体のデータをまるごと引き受けて解析することもある」点です。機械学習のすべてではもちろんないのですが、中にはビッグデータを力ずくで引き受けて解析するものもあるわけです。
統計学的手法と機械学習のちがいは、たとえて言えば「開票速報と開票作業のちがい」です。
衆参両院の国政選挙ともなりますと、投票日の夕方には各テレビ局が選挙特番を組んで視聴率を争います。だいたい夜7時くらいから始まりますね。
そうしますと、番組開始から1分もしないうちに「当確出ました。東京3区、悪山毒蔵さんです。痔民党、悪山毒蔵さん、当確です」などというように、「開票率0%」の段階で早々と当選確実が報じられるのをよく目にします。
もうお察しでしょうが、この開票速報は統計学的手法によっています。投票所における「出口調査」をもとに、その選挙区全体の得票状況を推計しているわけです。各テレビ局、そして各テレビ局に推計を提供する民間の統計会社は、しのぎを削ってその速さと精度を競っています。その努力にICT技術の発展もくわわり、ここ十数年ほどで開票速報の速度と精度は大きく改善されています。
つまり速い上にほとんど外れないのですが、これがせいぜい100人ほどを対象とした出口調査でなされているというのですから、統計学の威力はすさまじいものです。有権者数が十万人の選挙区でも、それくらいの人数をサンプリングすれば精度の高い予測ができてしまうのです。
これに対し、公務員の皆さんが総出で行う「開票作業」はビッグデータの解析に似ています。
なにしろ、投票箱の中に投じられた票は、主権者たる国民が憲法で保証された権利により投じた「神聖にして侵すべからざる清き一票」なのです。余すところなく、一票一票が尊重されなければなりません。白票だろうが、無効票だろうが、公務員としては一票一票すべてに扈従し跪拝するくらいの気持ちで大切にするでしょう。(休日出勤を強いられている上に、「開票速報」に「もう結果は出ている。キミたちの仕事に意味はない」と宣告されながら、深夜まで開いては集計、開いては集計という単調な作業まで強いられるのですから、本音はと言うと「全部燃えちまえばいいのに」でしょうが。)
つまり、ビッグデータを対象としてデータマイニングやディープラーニングを行う機械学習では、一部を抜き出すのではなく、ひとつも残すことなく全データを拾い上げるということです。

では次の記事では、機械学習のテクノロジーについて触れていきます。